Comentarii Adauga Comentariu
Queen 2.5
Qwen 2.5
Data: 19 septembrie 2024
În acest blog, explorăm detaliile noilor modele de limbaj din seria Qwen2.5 dezvoltate de Alibaba Cloud Dev Team. Echipa a creat o gamă de modele dense numai pentru decodor, șapte dintre ele fiind open-source, variind de la 0,5B la 72B parametri. Cercetările arată un interes semnificativ al utilizatorilor pentru modelele din intervalul de parametri 10-30B pentru utilizare în producție, precum și modelele 3B pentru aplicații mobile. Pentru a răspunde acestor nevoi, echipa are Qwen2.5-3B, Qwen2.5-14B și Qwen2.5-32B cu sursă deschisă. În plus, modele precum Qwen-Plus și Qwen-Turbo sunt disponibile prin serviciile API din Alibaba Cloud Model Studio.
Qwen2.5 vs Qwen2
Seria Qwen2.5 aduce mai multe upgrade-uri cheie în comparație cu seria Qwen2 :
- Open-source la scară completă: ca răspuns la cererea puternică a utilizatorilor pentru modele din gama 10-30B pentru producție și modele 3B pentru utilizare mobilă, Qwen2.5 își extinde ofertele open-source dincolo de cele patru modele Qwen2 (0,5B, 1,5B, 7B și 72B). Acesta adaugă două modele de dimensiuni medii rentabile — Qwen2.5-14B și Qwen2.5-32B — precum și Qwen2.5-3B optimizat pentru mobil. Aceste modele sunt extrem de competitive, Qwen2.5-32B depășind Qwen2-72B și Qwen2.5-14B depășind Qwen2-57B-A14B în evaluări cuprinzătoare.
- Set de date pre-antrenament mai mare și de calitate mai înaltă: setul de date pre-antrenament s-a extins semnificativ, crescând de la 7 trilioane de jetoane la 18 trilioane de jetoane, sporind profunzimea de antrenament a modelului.
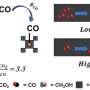
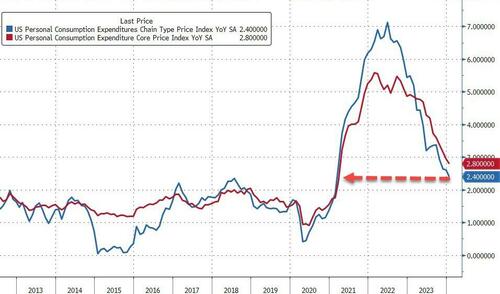
- Îmbunătățirea cunoștințelor: Qwen2.5 demonstrează cunoștințe mai mari în diferite benchmark-uri. De exemplu, scorurile MMLU pentru Qwen2.5-7B și Qwen2.5-72B au crescut la 74.2 și 86.1, comparativ cu 70.3 și 84.2 pentru modelele Qwen2, cu câștiguri substanțiale observate și în benchmark-uri precum GPQA, MMLU-Pro, MMLU-redux și ARC-c.
- Îmbunătățirea codării: capacitățile de codare ale Qwen2.5 s-au îmbunătățit semnificativ datorită progreselor în Qwen2.5-Coder. Qwen2.5-72B-Instruct îl depășește pe predecesorul său pe LiveCodeBench, MultiPL-E și MBPP, cu scoruri de 55,5, 75,1 și, respectiv, 88,2, față de 32,2, 69,2 și 80,2 pentru Qwen2-72B-Instruct.
- Îmbunătățirea matematică: Abilitatea matematică a lui Qwen2.5 a cunoscut, de asemenea, o îmbunătățire rapidă, cu scorurile la benchmarkul MATH crescând de la 52,9 și 69,0 pentru Qwen2-7B/72B-Instruct la 75,5 și 83,1 pentru modelele Qwen2.5.
- O mai bună aliniere a preferințelor umane: Qwen2.5 generează răspunsuri mai în concordanță cu preferințele umane. De exemplu, scorul Arena-Hard pentru Qwen2.5-72B-Instruct a crescut de la 48.1 la 81.2, iar scorul MT-Bench s-a îmbunătățit de la 9.12 la 9.35, comparativ cu Qwen2-72B-Instruct.
- Alte îmbunătățiri ale capacității de bază: modelele Qwen2.5 excelează în urmărirea instrucțiunilor, generarea de text lung (extinderea de la 1K la peste 8K jetoane), înțelegerea datelor structurate și producerea de rezultate structurate precum JSON. De asemenea, demonstrează o rezistență îmbunătățită la diverse solicitări ale sistemului, îmbunătățind jocul de rol și setarea condițiilor pentru chatbot.
Performanță și comparații
Performanță Qwen2.5-72B
| Seturi de date | Llama-3-70B | Mixtral-8x22B | Qwen2-72B | Qwen2.5-72B |
|---|---|---|---|---|
| MMLU | 79,5 | 77,8 | 84,2 | 86,1 |
| MATH | 42.5 | 41.7 | 50.9 | 62.1 |
| HumanEval | 48,2 | 46,3 | 64,6 | 59,1 |
| MBPP | 70,4 | 71,7 | 76,9 | 84,7 |
Concluzie
Modelele Qwen2.5 demonstrează un salt major față de generațiile anterioare și excelează în multiple domenii.
Qwen 2.5
Data: 19 septembrie 2024
În acest blog, explorăm detaliile noilor modele de limbaj din seria Qwen2.5 dezvoltate de Alibaba Cloud Dev Team. Echipa a creat o gamă de modele dense numai pentru decodor, șapte dintre ele fiind open-source, variind de la 0,5B la 72B parametri. Cercetările arată un interes semnificativ al utilizatorilor pentru modelele din intervalul de parametri 10-30B pentru utilizare în producție, precum și modelele 3B pentru aplicații mobile. Pentru a răspunde acestor nevoi, echipa are Qwen2.5-3B, Qwen2.5-14B și Qwen2.5-32B cu sursă deschisă. În plus, modele precum Qwen-Plus și Qwen-Turbo sunt disponibile prin serviciile API din Alibaba Cloud Model Studio.
Qwen 2.5
Data: 19 septembrie 2024
În acest blog, explorăm detaliile noilor modele de limbaj din seria Qwen2.5 dezvoltate de Alibaba Cloud Dev Team. Echipa a creat o gamă de modele dense numai pentru decodor, șapte dintre ele fiind open-source, variind de la 0,5B la 72B parametri. Cercetările arată un interes semnificativ al utilizatorilor pentru modelele din intervalul de parametri 10-30B pentru utilizare în producție, precum și modelele 3B pentru aplicații mobile. Pentru a răspunde acestor nevoi, echipa are Qwen2.5-3B, Qwen2.5-14B și Qwen2.5-32B cu sursă deschisă. În plus, modele precum Qwen-Plus și Qwen-Turbo sunt disponibile prin serviciile API din Alibaba Cloud Model Studio.
Qwen2.5 vs Qwen2
Seria Qwen2.5 aduce mai multe upgrade-uri cheie în comparație cu seria Qwen2 :
- Open-source la scară completă: ca răspuns la cererea puternică a utilizatorilor pentru modele din gama 10-30B pentru producție și modele 3B pentru utilizare mobilă, Qwen2.5 își extinde ofertele open-source dincolo de cele patru modele Qwen2 (0,5B, 1,5B, 7B și 72B). Acesta adaugă două modele de dimensiuni medii rentabile — Qwen2.5-14B și Qwen2.5-32B — precum și Qwen2.5-3B optimizat pentru mobil. Aceste modele sunt extrem de competitive, Qwen2.5-32B depășind Qwen2-72B și Qwen2.5-14B depășind Qwen2-57B-A14B în evaluări cuprinzătoare.
- Set de date pre-antrenament mai mare și de calitate mai înaltă: setul de date pre-antrenament s-a extins semnificativ, crescând de la 7 trilioane de jetoane la 18 trilioane de jetoane, sporind profunzimea de antrenament a modelului.
- Îmbunătățirea cunoștințelor: Qwen2.5 demonstrează cunoștințe mai mari în diferite benchmark-uri. De exemplu, scorurile MMLU pentru Qwen2.5-7B și Qwen2.5-72B au crescut la 74.2 și 86.1, comparativ cu 70.3 și 84.2 pentru modelele Qwen2, cu câștiguri substanțiale observate și în benchmark-uri precum GPQA, MMLU-Pro, MMLU-redux și ARC-c.
- Îmbunătățirea codării: capacitățile de codare ale Qwen2.5 s-au îmbunătățit semnificativ datorită progreselor în Qwen2.5-Coder. Qwen2.5-72B-Instruct îl depășește pe predecesorul său pe LiveCodeBench, MultiPL-E și MBPP, cu scoruri de 55,5, 75,1 și, respectiv, 88,2, față de 32,2, 69,2 și 80,2 pentru Qwen2-72B-Instruct.
- Îmbunătățirea matematică: Abilitatea matematică a lui Qwen2.5 a cunoscut, de asemenea, o îmbunătățire rapidă, cu scorurile la benchmarkul MATH crescând de la 52,9 și 69,0 pentru Qwen2-7B/72B-Instruct la 75,5 și 83,1 pentru modelele Qwen2.5.
- O mai bună aliniere a preferințelor umane: Qwen2.5 generează răspunsuri mai în concordanță cu preferințele umane. De exemplu, scorul Arena-Hard pentru Qwen2.5-72B-Instruct a crescut de la 48.1 la 81.2, iar scorul MT-Bench s-a îmbunătățit de la 9.12 la 9.35, comparativ cu Qwen2-72B-Instruct.
- Alte îmbunătățiri ale capacității de bază: modelele Qwen2.5 excelează în urmărirea instrucțiunilor, generarea de text lung (extinderea de la 1K la peste 8K jetoane), înțelegerea datelor structurate și producerea de rezultate structurate precum JSON. De asemenea, demonstrează o rezistență îmbunătățită la diverse solicitări ale sistemului, îmbunătățind jocul de rol și setarea condițiilor pentru chatbot.
Performanță și comparații
Performanță Qwen2.5-72B
| Seturi de date | Llama-3-70B | Mixtral-8x22B | Qwen2-72B | Qwen2.5-72B |
|---|---|---|---|---|
| MMLU | 79,5 | 77,8 | 84,2 | 86,1 |
| MATH | 42.5 | 41.7 | 50.9 | 62.1 |
| HumanEval | 48,2 | 46,3 | 64,6 | 59,1 |
| MBPP | 70,4 | 71,7 | 76,9 | 84,7 |
Concluzie
Modelele Qwen2.5 demonstrează un salt major față de generațiile anterioare și excelează în multiple domenii.
Qwen2.5 vs Qwen2
Seria Qwen2.5 aduce mai multe upgrade-uri cheie în comparație cu seria Qwen2 :
- Open-source la scară completă: ca răspuns la cererea puternică a utilizatorilor pentru modele din gama 10-30B pentru producție și modele 3B pentru utilizare mobilă...
- Set de date pre-antrenament mai mare și de calitate mai înaltă: setul de date pre-antrenament s-a extins semnificativ...
- Îmbunătățirea cunoștințelor: Qwen2.5 demonstrează cunoștințe mai mari în diferite benchmark-uri...
- Îmbunătățirea codării: capacitățile de codare ale Qwen2.5 s-au îmbunătățit semnificativ...
- Îmbunătățirea matematică: abilitatea matematică a lui Qwen2.5 a cunoscut o îmbunătățire rapidă...
- O mai bună aliniere a preferințelor umane: Qwen2.5 generează răspunsuri mai în concordanță cu preferințele umane...
- Alte îmbunătățiri ale capacității de bază: modelele Qwen2.5 excelează în urmărirea instrucțiunilor...
Card model Qwen2.5
| Modele | Params | Parametrii non-Emb | Straturi | Capete (KV) | Încorporarea cravatei | Lungimea contextului | Lungimea generației | Licenţă |
|---|---|---|---|---|---|---|---|---|
| Qwen2.5-0.5B | 0,49B | 0,36B | 24 | 14 / 2 | Da | 32K | 8K | Apache 2.0 |
| Qwen2.5-1.5B | 1,54B | 1,31B | 28 | 12 / 2 | Da | 32K | 8K | Apache 2.0 |
| Qwen2.5-3B | 3.09B | 2,77B | 36 | 16 / 2 | Da | 32K | 8K | Cercetarea Qwen |
| Qwen2.5-7B | 7,61B | 6,53B | 28 | 28 / 4 | Nu | 128K | 8K | Apache 2.0 |
| Qwen2.5-14B | 14.7B | 13.1B | 48 | 40 / 8 | Nu | 128K | 8K | Apache 2.0 |
| Qwen2.5-32B | 32,5B | 31.0B | 64 | 40 / 8 | Nu | 128K | 8K | Apache 2.0 |
| Qwen2.5-72B | 72,7B | 70,0B | 80 | 64 / 8 | Nu | 128K | 8K | Qwen |
Performanțe Qwen2.5
Performanța modelelor Qwen2.5 este evaluată pe o gamă largă de sarcini, incluzând matematică, codare și multilingvism.
Performanță Qwen2.5-72B
Modelul de bază Qwen2.5-72B iese în evidență prin depășirea semnificativă a altor modele din categoria sa într-un spectru larg de sarcini.
Performanță Qwen2.5-14B/32B
Modelele Qwen2.5-14B și Qwen2.5-32B oferă performanțe robuste în sarcini generale precum MMLU și BBH...
Performanță Qwen2.5-7B
Modelul Qwen2.5-7B depășește atât predecesorii, cât și concurenții săi într-o gamă largă de benchmark-uri.
Concluzii
Modelele Qwen2.5 reprezintă un progres semnificativ, oferind performanțe competitive într-o gamă variată de domenii și fiind optimizate pentru utilizare în aplicații diverse.





















































Comentarii:
Adauga Comentariu